
Teapot Pouring


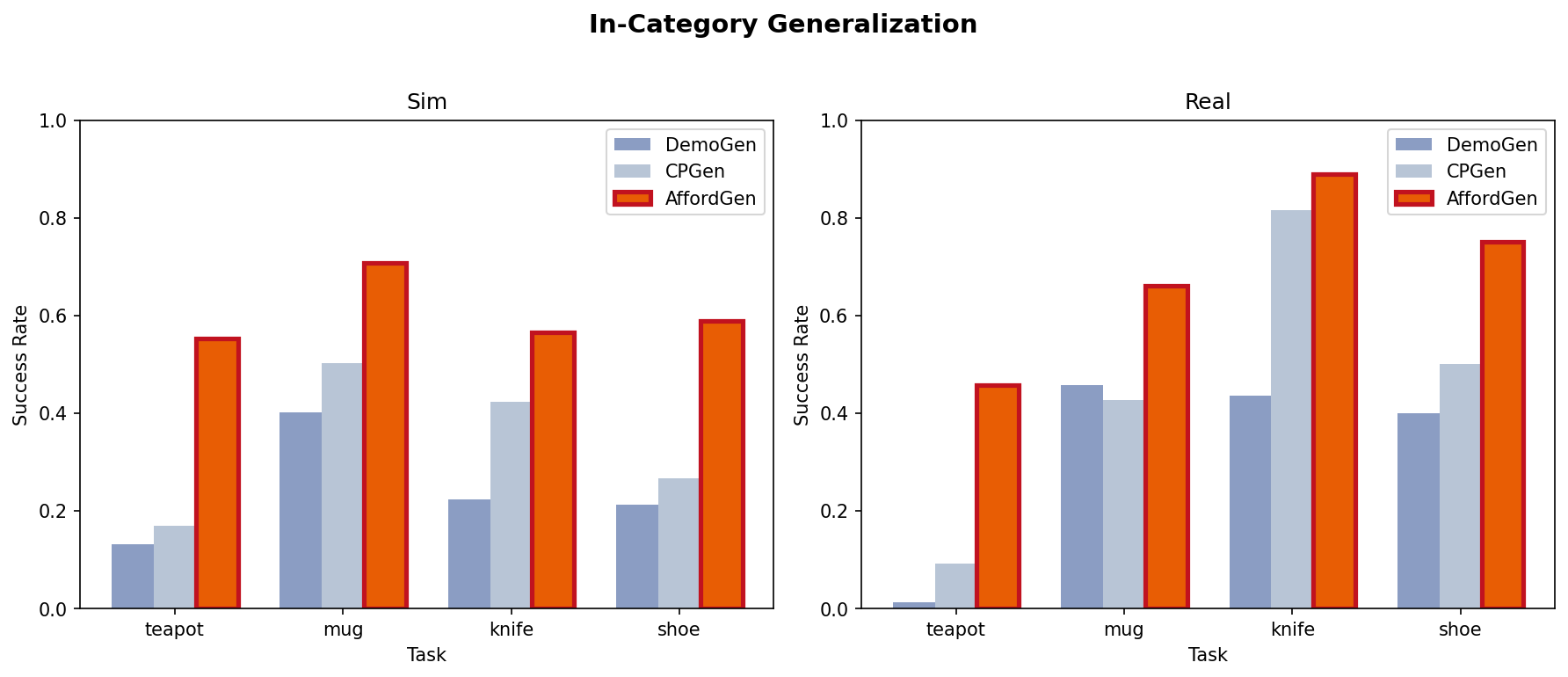
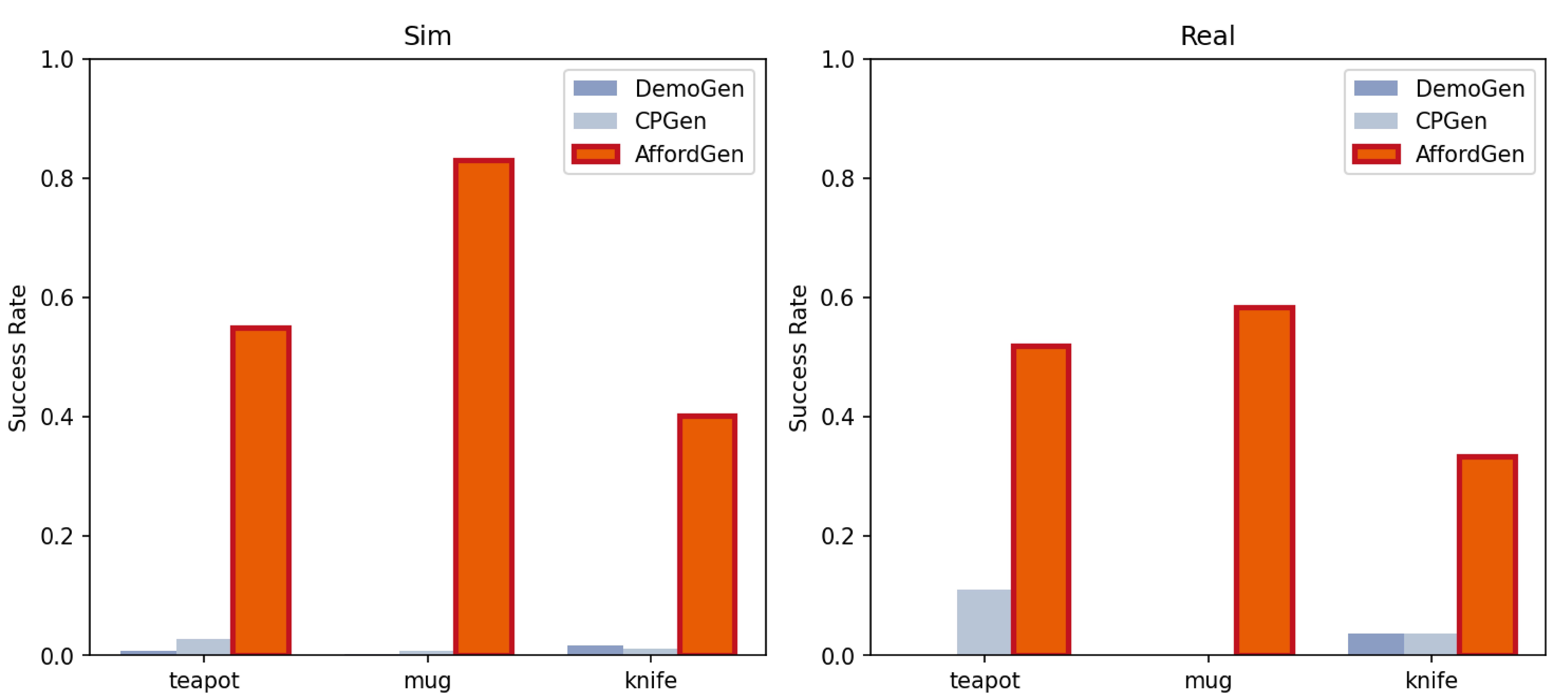
Despite the recent success of modern imitation learning methods in robot manipulation, their performance is often constrained by geometric variations due to limited data diversity. Leveraging powerful 3D generative models and semantic foundation models (VFMs), the proposed AffordGen framework overcomes this limitation by utilizing the semantic correspondence of meaningful keypoints across large-scale 3D meshes to generate new robot manipulation trajectories. This large-scale, affordance-aware dataset is then used to train a robust, closed-loop visuomotor policy, combining the semantic generalizability of affordances with the reactive robustness of end-to-end learning. Experiments in simulation and the real world show that policies trained with AffordGen achieve high success rates and enable zero-shot generalization to truly unseen objects, significantly improving data efficiency in robot learning.
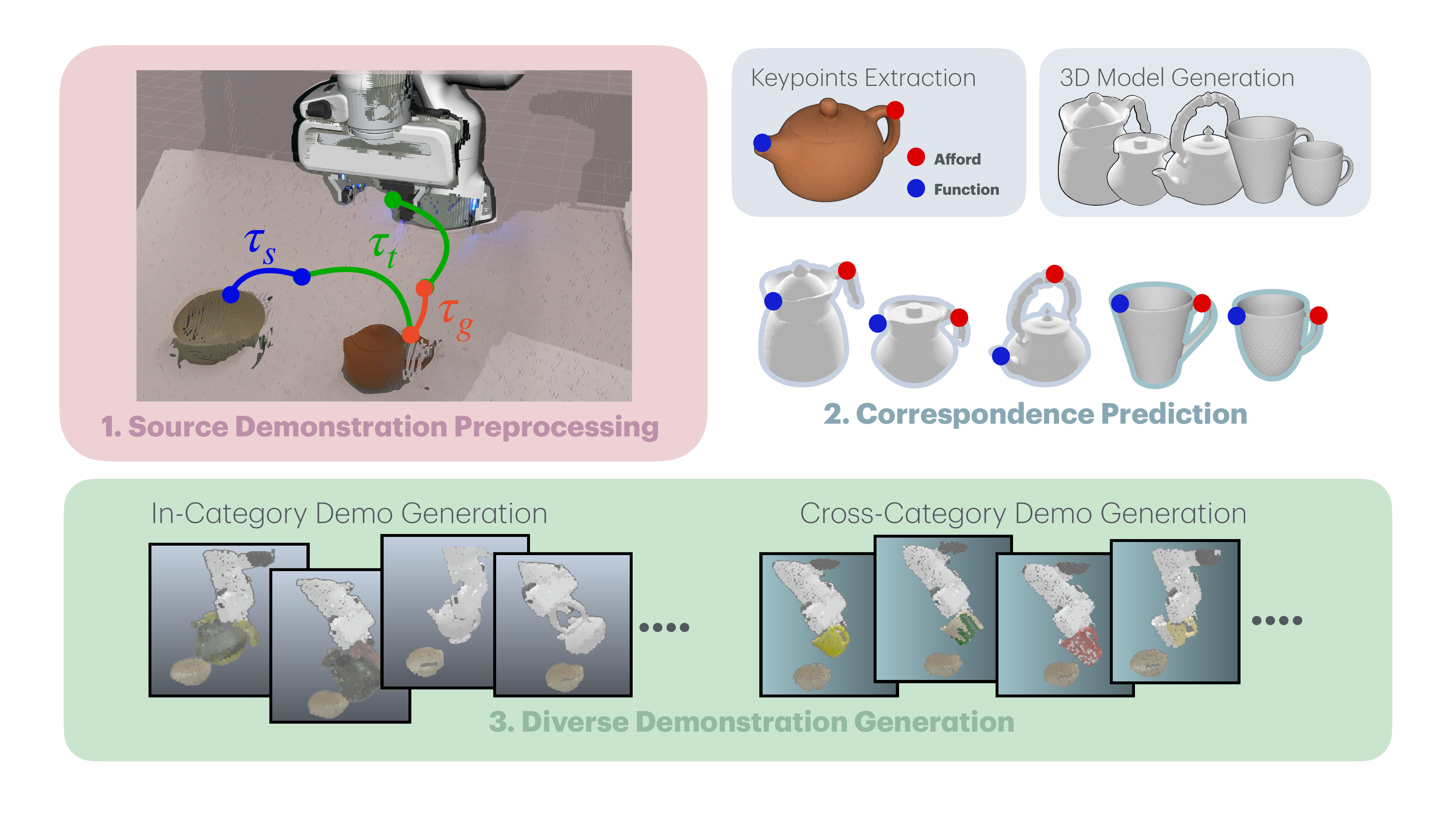
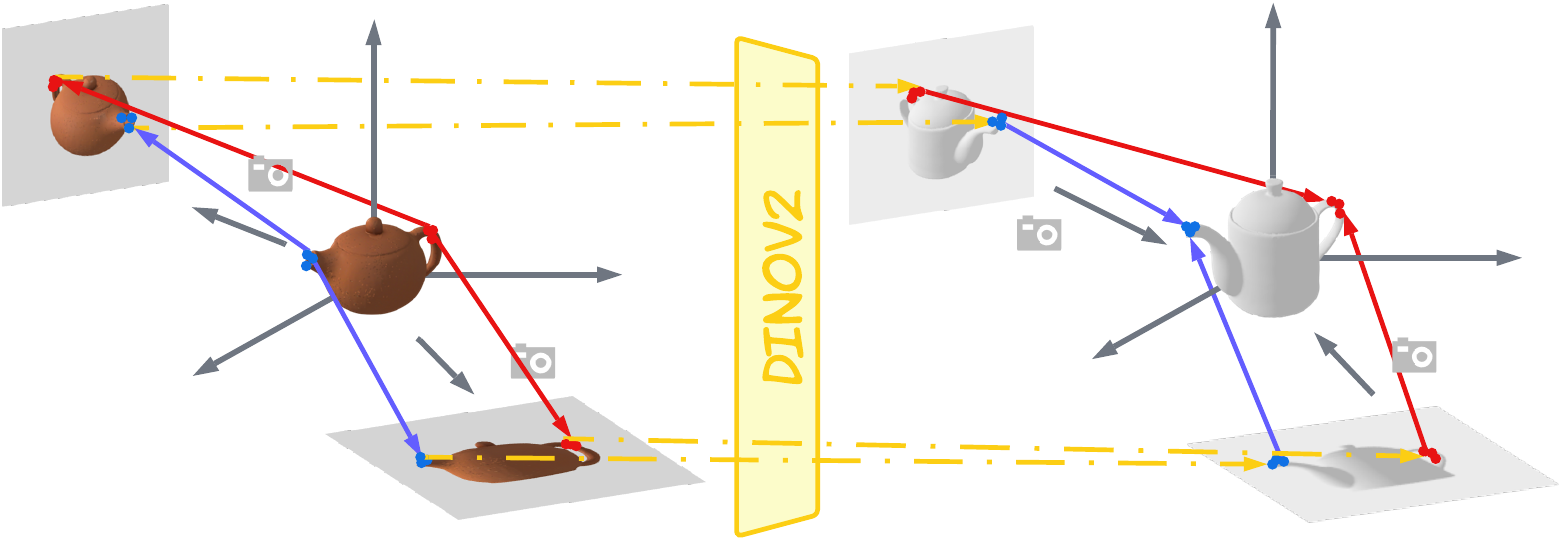
AffordGen first decomposes a source demonstration, establishes semantic keypoint correspondence on 3D meshes, and then replays grasp and skill segments to generate diverse demonstrations for new objects.
Each card shows paired simulation and real-world examples generated from the same manipulation objective.












@article{zhang2026affordgen,
title={AffordGen: Generating Diverse Demonstrations for Generalizable Object Manipulation with Affordance Correspondence},
author={Zhang, Jiawei and Hu, Kaizhe and Huang, Yingqian and Ju, Yuanchen and Xue, Zhengrong and Xu, Huazhe},
journal={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026},
url={https://arxiv.org/abs/2604.10579}
}